I've written this tutorial mostly with the people using the Hadoop machines at the University of Sheffield in mind. However, except the machine related variables you can follow this tutorial on any Hadoop machine. You need to have Hadoop already installed on your system. The commands were tested with the Cloudera CDH3 update 5 release under Unix on the Derwent machine.
The tutorial will start from beginner level to being able to write and run quickly custom Hadoop MapReduce jobs. I'll also discuss basic commands and using the file system.
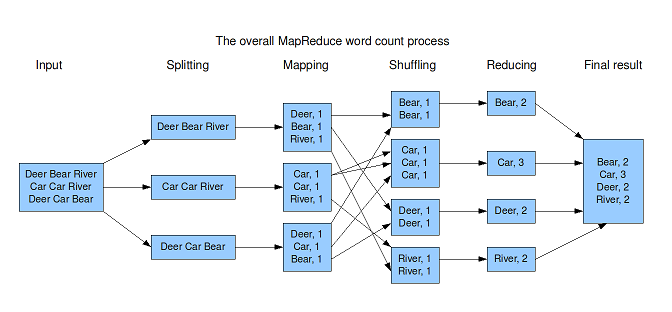
Hadoop is an open-source framework which allows fast, reliable and scalable distributed conmputing and storage. It is based on the divide an conquer method. It allows specification of two main methods: the mapper and the reducer. The mappers process disjoint parts of the data in parralel and output (key,value) pairs. The results of the mappers are aggregated, sorted by key and sent to the reducers. The output consists of the outputs of each reducer concatenated.
I should say from the start that Hadoop can not accomplish any computational task. Usually, applications have to be completely rethought to fit into the MapReduce paradigm and this might not be productive (see Recommended reading for algorithm design). It might also not be productive to compute in parallel, mostly because if the data is not large enough the overload for splitting and coordinating the jobs might be higher than running on a single machine. Hadoop works best when you are I/O bounded: processing takes far less time than random disk access and the data can be read sequentially. For example, this is the case of large tweets collections.
As a general rule of thumb, Hadoop is most useful when you need results aggregated over large data where any part is not dependent one the other (e.g. word count, co-occurrence count). Hadoop can also be used only for its functionality of eleviating I/O bounds (e.g. filter a large file for content, keep only English tweets).
All my examples will be run on tweets. An sample of such file can be downloaded here. The tweets are in JSON format, one tweet/line. Furthermore, all tweets have an extra 'analysis'/'tokens'/'all' field which contains a list of all tokens obtained using the Trendminer preprocessing pipeline.
Hadoop works with its distributed file system (HDFS). HDFS stores files over the network where they are replicated in case of failure and allows sequential reading of lines rather than random disk access.
In order to be usable with Hadoop, all files should be loaded on HDFS first. The output of the jobs is also stored on HDFS. In order to access HDFS, you need to run commands starting with:
hadoop fsEach user has a home on HDFS, usually under /user. Some useful commands are:
name='user'
hadoop fs -ls / # lists the directories in root
hadoop fs -mkdir /user/$name/data # creates a directory under the user's home
hadoop fs -put tweets /user/$name/data # uploads the tweets file to homeA web interface with HDFS information and browsing (available only from within SDCS):
http://derwent.dcs.shef.ac.uk:50070/dfshealth.jspI will use Hadoop Streaming to describe running jobs. There are broadly two options: Streaming and Native. The streaming version is used for quick prototpying and writing jobs. If you want to do something more ellaborate and need to have access to all of Hadoop's functionality you should use the Native option.
You first need to identify the Hadoop Streaming jar.
hadoop_streaming='/usr/lib/hadoop-0.20/contrib/streaming/hadoop-streaming-0.20.2-cdh3u5.jar' In Hadoop you only have to specify the mapper and the reducer. The general Hadoop pipeline is:
I will use Python for writing scripts, but any language can be used as long as the input and output format remains the same.
The mapper receives as input a file and must output (key,value) pairs. Each line represents a separate input. In this case the output must be in the format: key<TAB>value (one/line). The value might be missing if you don't plan on using a reducer.
A simple example for word counting tokens in tweets is:
wc-map.sh:
#!/usr/bin/python
import json
import sys
for line in sys.stdin:
try:
tweet=json.loads(line)
tokenset=[x.lower() for x in tweet['analysis']['tokens']['all']]
tokens=set(tokenset)
for token in tokens:
print json.dumps(token.lower()),'\t',1
except:
passThe mapper receives as input key<TAB>value pairs and outputs key<TAB>value pairs which form the final output. The script can assume the lines are sorted by key so for example all lines having the same key will be adjacent.
The usual reducer is the one which sums the values of all lines having the same key:
wc-red.sh:
#!/usr/bin/python
import sys
prevWord=""
valueTotal=0
for line in sys.stdin:
(word,values)=line.split('\t')
value=int(values.strip())
if word==prevWord or prevWord=='':
valueTotal=valueTotal+value
prevWord=word
else:
print prevWord,'\t',valueTotal
prevWord=word
valueTotal=value
print prevWord,'\t',valueTotalBefore running the scripts with Hadoop, you should check the code locally. Hadoop doesn't allow you to easily identify errors in your code. You can simulate a Hadoop process with the following command:
cat tweets | python ./wc-map.sh | sort | python ./wc-red.sh > outputNotice the output contains word<TAB>frequency pairs sorted alphabetically by word. This happens because of the automatic sorting step performed between the map and the reduce jobs.
All the components are now in place to run your first Hadoop job. For this, you need to specify:
hadoop jar $hadoop_streaming -mapper wc-map.sh -reducer wc-red.sh -input /user/$name/data/tweets -output output1 -file wc-map.sh -file wc-red.shHadoop stores the results in shards (usually called part-0000x) in the specified folder. Note the output folder must not exist beforehand, otherwise the job will not run!
You can now examine the results by copying the output file locally:
hadoop fs -cat /user/$name/output1/part-00000 > outputhadoop # saves a file locally
hadoop fs -rmr /user/$name/output1 # removes the output folderThe jobtracker can be accesed usualy on port 50030 from a browser. You can see all jobs, their status, etc.:
derwent.dcs.shef.ac.uk:50030/jobtracker.jspInformation about all jobs can be also accessed from bash:
hadoop jobUseful examples include:
hadoop job -list # lists all jobs
hadoop job -kill <job-id> # kills an active jobThe number of mappers is set automatically by the job based on the input files size (usually one mapper processes shards of 128MB). The number of reducers is set automatically but can be altered by using the flag:
-D mapred.reduce.tasks=$noredNote: If you start running a job from bash and press <Ctrl-C>, that doesn't stop the job from running. You have to stop the job yourself with the command above.
To make storing data more efficient, Hadoop works best in combination with LZO compression. This is a block compression algorithm, which means Hadoop can split a big file into chunks to send to worker nodes without needing to uncompress files. You first need to have the 'lzop' utility installed:
sudo apt-get install lzop
lzop -9U tweets # compresses the tweets file to a file called tweets.lzo The U flag removes the original file, in this case tweets.lzo
lzop -d tweets.lzo # decompresses the tweets.lzo file to tweets. In order for Hadoop to actually be able to split an LZO file and hence to use multiple mappers on a large input file, you need to first index the file on HDFS. This can be done either with one process or in parallel:
hadoop_lzo='/usr/lib/hadoop-0.20/lib/hadoop-lzo-0.4.15.jar'
hadoop fs -put tweets.lzo /user/$name/data/ # upload the file to HDFS
hadoop jar $hadoop_lzo com.hadoop.compression.lzo.LzoIndexer /user/$name/data/tweets.lzo
hadoop jar $hadoop_lzo com.hadoop.compression.lzo.DistributedLzoIndexer /user/$name/data/tweets.lzoTo use compressed input add these flags to the run job command:
-inputformat com.hadoop.mapred.DeprecatedLzoTextInputFormat
-D stream.map.input.ignoreKey=true # needs to be the first flag For compression of the output add the flags:
-jobconf mapred.output.compress=true
-jobconf mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec It's common that you need to use other files inside a map or reduce script (e.g. dictionaries). The distributed cache copies a file to each node for use inside scripts. For this reason, these files have to quite small in size.
To use these files you should first load the file to HDFS and then add the flag:
hdfs='hdfs://localhost:8020' # you need to identify this address of the hdfs, it might be different!
-cacheFile "$hdfs/user/$name/dictionary#dict" where /user/$name/dictionary is the location of the external file and the string after the # is the name of the file as it will be accessible from inside the script.
In order to filter a large set of documents based on their content we are again in a situation where I/O takes much more time than the processing operation and this can be performed on each document independently of others. This fits well into the Hadoop setup, but no aggregation needs to be performed. Thus, we can just drop the reducer and only use the mapper which outputs only the documents that pass the filter specified in the file. In this case, we want to filter all tweets in a large file (1 tweet/line) which are geo-tagged and are within a rectangle containing the UK.
filter-uk.sh:
#!/usr/bin/python
import json
import sys
for line in sys.stdin:
try:
tweet=json.loads(line)
if tweet["geo"]:
lat=float(tweet["geo"]["coordinates"][0])
long=float(tweet["geo"]["coordinates"][1])
if (long<1.40) and (long>-5.8) and (lat<58.7) and (lat>49.9):
print json.dumps(tweet)
except:
passTo run the job:
hadoop jar $hadoop_streaming -D stream.map.input.ignoreKey=true -mapper filter-uk.sh -input /user/$name/tweets.lzo -output output2 -file filter-uk.sh -inputformat com.hadoop.mapred.DeprecatedLzoTextInputFormat In this example we create a vector space representation of a set of tweets. We want to create a list of (day,user,word,value) where the value is the word frequency for a user on a each day. The day is counted in days compared to a reference date specified in dref:
vs.sh:
#!/usr/bin/python
import sys
import json
import datetime
import time
fdict=file("dict","r")
d={}
for line in fdict:
l=line.strip().split()
d[l[1]]=l[0]
fdict.close()
dref=datetime.datetime(*time.strptime('Jun 14 2012','%b %d %Y')[0:5])
for line in sys.stdin:
try:
tweet=json.loads(line)
da=datetime.datetime(*time.strptime(tweet['created_at'],'%a %b %d %H:%M:%S +0000 %Y')[0:5])
did=(da-dref).days
uid=int(tweet[tweet['user']['id']])
tokens=[x.lower() for x in tweet['analysis']['tokens']['all']]
for i in tokens:
try:
wid=d[i]
print did,uid,wid,'\t',1
except:
continue
except:
passAs reducer we will use the standard reducer which adds together values for the same key, in case the combination of day, user and word. The dictionary is a file which maps each token to a number. Sample file is here.
hadoop jar $hadoop_streaming -D stream.map.input.ignoreKey=true -mapper vs.sh -reducer wc-red.sh -input /user/$name/tweets.lzo -output output3 -file vs.sh -inputformat com.hadoop.mapred.DeprecatedLzoTextInputFormat -cacheFile "hdfs://localhost:8020/user/daniel/dictionary#dict"In this example we run a Java compiled jar which uses Hadoop. It is the tweet preprocessing tool used to tokenise and produce the 'analysis'/'tokens'/'all' field in the JSON. We upload a tweet file and run the jar available for download here:
hadoop fs -put tweets2.lzo /user/$name/data/tweets2.lzo
hadoop jar HadoopTwitterPreprocessingTool.jar -i $hdfs/user/$name/data/tweets2.lzo -o $hdfs/user/$name/output4 -m TOKENISE -m LANG_ID -ri-m -ri are options of the jar. A full description of the tool and all its options.
There are a few configuration files, usually found:
/etc/hadoop/conf/hdfs-site.xml # for HDFS
/etc/hadoop/conf/mapred-site.xml # for Map ReduceTo start/stop services related do hadoop run:
for service in /etc/init.d/hadoop-0.20-*; do sudo $service stop; done
for service in /etc/init.d/hadoop-0.20-*; do sudo $service start; doneThe safe mode will activate if the disk fills up, which means no command can be run. To exit this mode after you've made disk space available run:
hadoop dfsadmin -safemode leaveApache Hadoop: Best Practices and Anti-Patterns - Best for general advice
Data-Intensive Text Processing with MapReduce - Best for algorithm design
Hadoop in Action - Best for basic to advanced programming under Java
Big Data - Best for high level scalable solutions
Mahout in Action - Best for running machine learning algorithms
If you are using Ribble, the different variables have these values:
hadoop_lzo='/usr/lib/hadoop/lib/hadoop-lzo-cdh4-0.4.15-gplextras.jar'
hadoop_streaming='/opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.3.0.jar'
hdfs='hdfs://nn-01:8020'